
Over the last months I’ve been working with great team for an excellent client to build a cloud native application that does some interesting things. We decided very early on in the process to develop this application to be scalable, available, distributed, and performance capable way.
At the highest logical level, the application/systems stack looks like the stack in figure 1.

Figure 1: The Stack
Once you use a stack like this and deploy the system it can become challenging at times to describe things. I’ve used a tool created by the team at AKF Partners call the Scale Cube.
I have posted about that in more detail in my write up called Scale Planning and the AKF Scale Cube
.
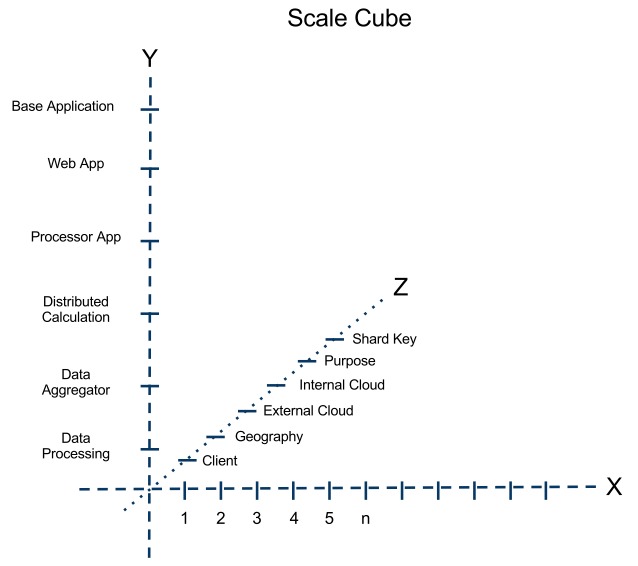
Figure 2: AKF Scale Cube Example
I have found the scale cube a quick and easy way to explain and often justify my choices regarding this and other systems when faced with the inevitable question, “isn’t that just premature scaling?” Planning is never premature otherwise you just did not bother to have a plan in the first place which leads to a lot of wasted time. I don’t like that type of situation. Time is much to valuable.
There are a lot of things one might do with an application stack like this one. In this particular case, it is a custom business analytics platform for near real time analytics and data crunching. This article isn’t to go into the full details of what this particular application does. I’ll save that for another day.
So, what is this stack and and what can it do fundamentally?
It is an application development environment that includes:
A secure web framework (LIFT)
A powerful programming language (Scala)
The tried and true JVM (jetty/java 1.6)
A distributed compute grid (GridGain) to spread the load across nodes
Virtual servers (EC2 AMI’s) that run
A great linux distro (Ubuntu)
It does map reduce, distributed key value data storage, Solr compatible search, distributed compute grid functions w/ some nifty auto-deploy features, serves web pages fast, and provides a secure web framework. In short, and in my own parlance, it is a series of tools and services that can be used to develop scalable data intensive cloud native applications
using public, private, or hybrid cloud deployment patterns.
(See NIST Cloud Definition for more details).
The actual deployment and operations of this stack is, of course, more complex than the simply logical diagram belies. We wanted to be able to deploy many times per day. So, we can’t forget our tool set that makes the stack smooth and shiny even when doing multiple deployes per day. For that we you need something that looks like the following; the systems management and development tool stacks.
- Tool for systems configuration management with Ruby
- Excellent Continuous Integration and Deployment tools
- Best Source Control Management around
- Best SaaS implementation of the best SCM around
- The developer IDE we standardized on across Windows, Linux, and OSX
- Simple Build Tool for Scala. Don’t compile code without it.
One Awesome DevOps Oriented Engineering Team
- Do not attempt this without a good team.
This set of tools allows us to deploy this distributed and mulit-faceted application several times per day if need be and do it in a way that is clear, documented, repeatable, and not a barrier to on-going development. There is a great deal of inherent value in this set of tools.
Learning to use this stack and set of tools was not necessarily easy but the good stuff never is particularly easy is easy in my experience. The system is engineered to scale, be highly available, performant and cloud native. As of right now, we’ve deployed it to work well and as we continue our testing of the applications we have running on it now we are beginning to scale out and up, load a LOT more data daily, and gather valuable customer feedback. This is very exciting and rewarding to my inner geek. But, at the end of the day, I think it’s just good engineering and planning.
This is not even close to the only way you could build a system like this. You could...
use the Hadoop/HDFS stack
use Actors/Akka instead of GridGain
could use HBase instead of Riak
could use java instead of scala (or numerous other languages...) - I actually have another project that’s kind of similar in architecture but a totally different stack! More on that another day...
use play instead of lift
use tomcat instead of jetty
etc...etc.
This is what, after much experimentation and effort, is working well for us. There are still unsolved problems of course. Some of which I actually alluded to in my
. Most days I feel like we’re just scratching the surface. Other days I feel like I’m just figuring out how to implement stuff that was essentially invented and published in the early 70’s. While we still have problems to solve we have a framework from which to attack them aggressively and successfully day by day.
Other related Posts
:
- A little bit about using multiple types of data stores for a project (hint, we all do it anyway)

{kind=link}